Object detection has become a cornerstone of modern artificial intelligence, powering applications such as autonomous vehicles, surveillance systems, and augmented reality. Among the most popular models in this space is the YOLO (You Only Look Once) family, known for its speed and efficiency. The latest version, developed by Ultralytics, introduces significant improvements in performance, flexibility, and usability.
In this blog, we will explore YOLOv8, its architecture, features, and why it stands out in real-time object detection.
What is YOLOv8?
YOLOv8 is the newest iteration in the YOLO series of object detection models. Unlike traditional detection systems that process images in multiple stages, YOLO models perform detection in a single forward pass, making them extremely fast.
YOLOv8 builds upon previous versions by introducing an anchor-free detection mechanism, improved backbone networks, and better training strategies. These enhancements make it more accurate and easier to implement across various applications.
Key Features of YOLOv8
1. Anchor-Free Detection
Earlier YOLO versions relied on predefined anchor boxes to predict object locations. YOLOv8 removes this dependency, simplifying the training process and improving detection accuracy, especially for objects of varying sizes.
2. Improved Backbone and Neck Architecture
YOLOv8 uses an optimized backbone for feature extraction and an enhanced neck (feature pyramid network) to better capture multi-scale features. This ensures improved detection for both small and large objects.
3. Decoupled Head Design
The model separates classification and bounding box regression tasks into different branches. This decoupled head improves learning efficiency and leads to better overall performance.
4. Scalability
YOLOv8 comes in multiple variants (Nano, Small, Medium, Large, and Extra Large), allowing developers to choose models based on their computational constraints and performance requirements.
5. Multi-Task Support
Beyond object detection, YOLOv8 supports:
- Image classification
- Instance segmentation
- Pose estimation
This versatility makes it a comprehensive computer vision solution.
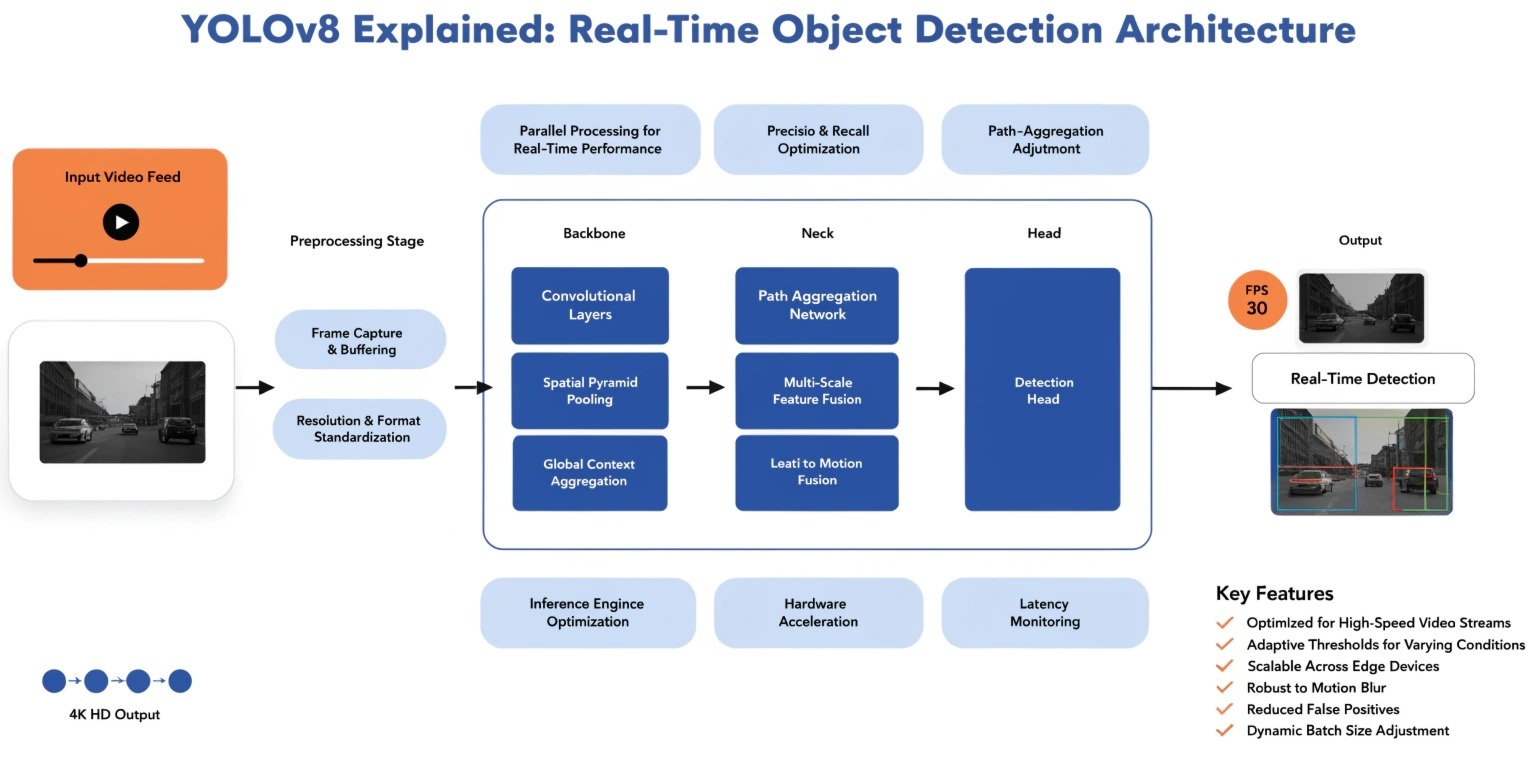
YOLOv8 Architecture Overview
The YOLOv8 architecture consists of three main components:
1. Backbone
The backbone is responsible for extracting features from the input image. YOLOv8 uses a CNN-based architecture that captures spatial and semantic information effectively.
2. Neck
The neck aggregates features from different layers using techniques like feature pyramid networks (FPN). This helps detect objects at multiple scales.
3. Head
The head predicts bounding boxes, class probabilities, and confidence scores. With its anchor-free and decoupled design, YOLOv8 achieves higher precision and faster inference.
How YOLOv8 Works
- Input Image Processing:
- The image is resized and normalized before being fed into the model.
- Feature Extraction:
- The backbone extracts important features such as edges, shapes, and textures.
- Feature Fusion:
- The neck combines features from different layers to improve detection across scales.
- Prediction:
- The head outputs bounding boxes, class labels, and confidence scores in a single pass.
This one-stage detection approach is what makes YOLOv8 highly efficient compared to traditional two-stage detectors.
Advantages of YOLOv8
- Real-Time Performance: Suitable for applications requiring instant detection.
- High Accuracy: Improved architecture enhances detection precision.
- Ease of Use: Simplified training and deployment processes.
- Flexibility: Works across multiple computer vision tasks.
- Reduced Complexity: Anchor-free design eliminates manual tuning.
Real-World Applications
YOLOv8 is widely used across industries:
- Autonomous Vehicles: Detect pedestrians, vehicles, and road signs.
- Healthcare: Identify anomalies in medical imaging.
- Retail: Monitor customer behavior and inventory.
- Security & Surveillance: Real-time threat detection.
- Agriculture: Detect crop diseases and monitor growth.
YOLOv8 vs Previous Versions
FeatureYOLOv5YOLOv7YOLOv8Anchor-BasedYesYesNoArchitectureCNN-basedOptimized CNNAdvanced CNNPerformanceHighVery HighSuperiorFlexibilityModerateHighVery High
YOLOv8’s anchor-free approach and multi-task capabilities clearly set it apart from earlier versions.
Challenges and Considerations
- Hardware Requirements: Larger models require powerful GPUs.
- Data Dependency: Performance depends heavily on training data quality.
- Fine-Tuning Needed: Custom datasets may require parameter adjustments.
Conclusion
YOLOv8 represents a major step forward in real-time object detection. With its anchor-free design, improved architecture, and multi-task capabilities, it offers a powerful and flexible solution for modern AI applications.
Whether you are building a smart surveillance system, an autonomous vehicle, or a retail analytics platform, YOLOv8 provides the speed and accuracy needed to succeed in today’s data-driven world.
As computer vision continues to evolve, YOLOv8 sets a new benchmark for efficiency, making it an essential tool for developers and AI practitioners.

