Natural Language Processing (NLP) enables machines to understand and generate human language. However, before an AI model can process text, the raw text must first be converted into smaller units called tokens. This process is known as tokenization.
Tokenization is one of the most important steps in preparing textual data for machine learning models. It determines how text is split into manageable pieces that models can interpret and analyze. Modern NLP systems rely heavily on subword tokenization techniques to balance vocabulary size and language understanding.
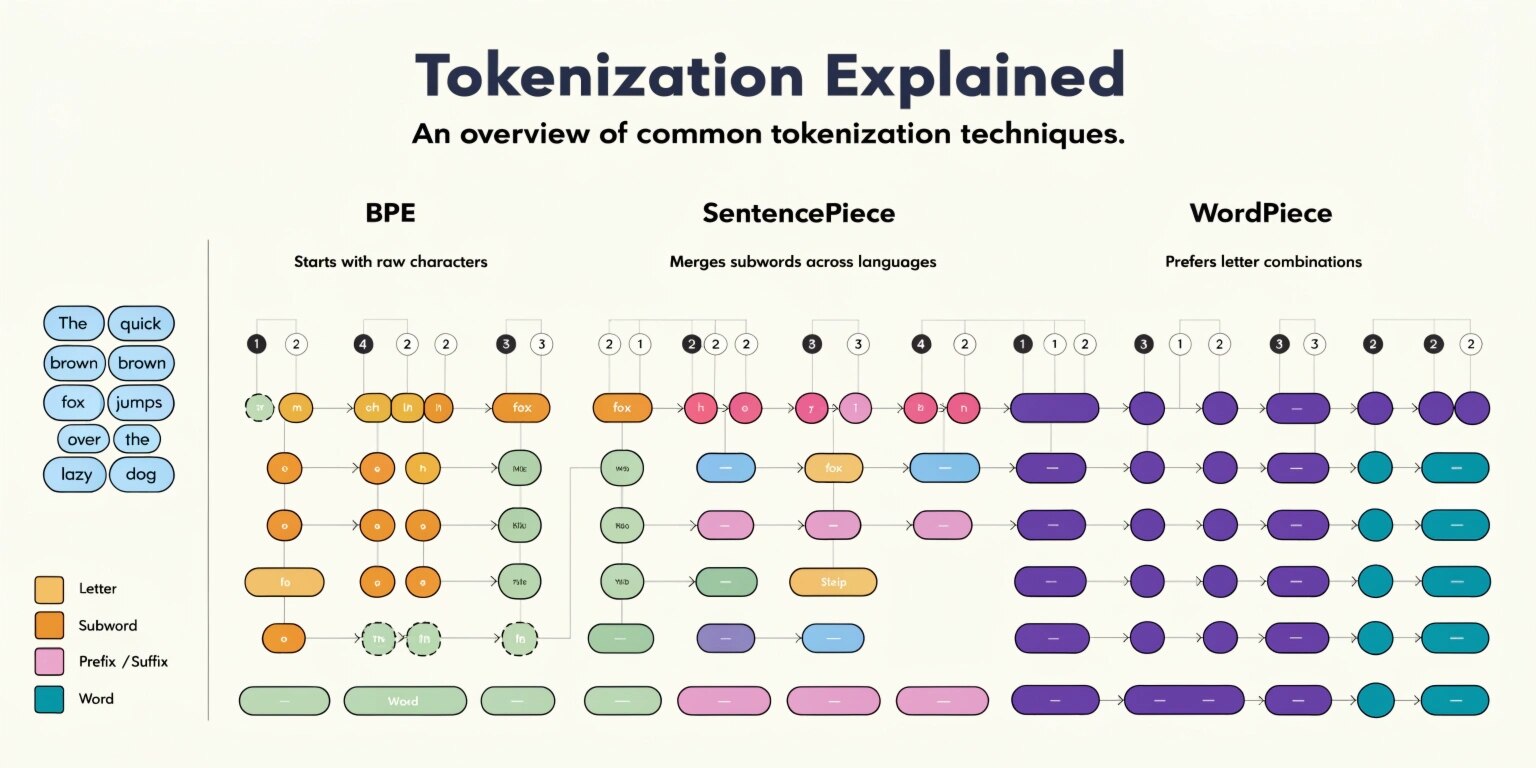
Three of the most widely used tokenization techniques today are Byte Pair Encoding (BPE), WordPiece, and SentencePiece. These methods allow language models to efficiently process large vocabularies and handle unknown words effectively.
What Is Tokenization?
Tokenization is the process of breaking text into smaller units called tokens. Tokens can represent:
- Words
- Characters
- Subwords
- Phrases
For example, consider the sentence:
"Artificial intelligence is transforming industries."
A simple tokenization approach might produce:
Artificial | intelligence | is | transforming | industries
However, modern NLP models often use subword tokenization, which breaks complex words into smaller meaningful units:
Artificial | intelligence | is | transform | ing | industries
Subword tokenization helps models understand rare words, prefixes, and suffixes while maintaining a manageable vocabulary size.
Byte Pair Encoding (BPE)
Byte Pair Encoding (BPE) is one of the earliest and most influential subword tokenization methods used in NLP.
Originally developed as a compression algorithm, BPE was later adapted for language modeling. The method works by repeatedly merging the most frequently occurring pairs of characters or subwords in a dataset.
How BPE Works
- Start with characters as the base vocabulary.
- Count the frequency of character pairs in the dataset.
- Merge the most frequent pair into a new token.
- Repeat the process until the desired vocabulary size is reached.
For example:
low
lower
lowest
The algorithm may merge characters such as lo, low, and er based on frequency.
Advantages of BPE
- Reduces vocabulary size
- Handles rare words effectively
- Improves memory efficiency
BPE became widely used in early neural machine translation systems and transformer-based models.
WordPiece Tokenization
WordPiece is another popular tokenization method used in many modern language models. It was originally developed for large-scale language processing systems.
Unlike BPE, which merges the most frequent character pairs, WordPiece merges tokens based on probability and likelihood improvements in the language model.
How WordPiece Works
WordPiece starts with characters as tokens and gradually merges them to form subwords that maximize the likelihood of the training corpus.
For example, the word:
"unhappiness"
May be tokenized as:
un | happy | ness
Unknown words are broken into smaller subwords using prefixes and suffixes.
Benefits of WordPiece
- Efficient handling of rare or unseen words
- Smaller vocabulary compared to word-level tokenization
- Improved performance in language models
WordPiece is commonly used in transformer architectures designed for deep NLP tasks.
SentencePiece Tokenization
SentencePiece is a language-independent tokenization method designed to simplify the NLP preprocessing pipeline.
Unlike BPE and WordPiece, which rely on pre-tokenized text, SentencePiece operates directly on raw text without requiring spaces or word boundaries.
This makes it particularly useful for languages where word boundaries are not clearly defined.
How SentencePiece Works
SentencePiece treats text as a sequence of Unicode characters and applies algorithms such as:
- BPE-based segmentation
- Unigram language models
It automatically determines the optimal tokenization based on statistical patterns in the training data.
Advantages of SentencePiece
- Works with raw text without preprocessing
- Supports multiple languages effectively
- Handles languages without spaces (e.g., Japanese or Chinese)
Because of its flexibility, SentencePiece has become widely adopted in multilingual AI systems.
Why Subword Tokenization Is Important
Traditional word-level tokenization struggles with large vocabularies and unknown words. Subword tokenization solves these problems by breaking words into smaller meaningful components.
Benefits include:
Handling Rare Words
Models can process words they have never seen before by combining subword units.
Reduced Vocabulary Size
Instead of millions of unique words, models work with a smaller set of subwords.
Better Language Understanding
Subwords capture prefixes, suffixes, and word structures that improve semantic understanding.
These advantages make subword tokenization essential for modern transformer-based language models.
Choosing the Right Tokenization Method
Each tokenization technique has strengths depending on the use case.
BPE is simple and efficient, making it suitable for many NLP tasks.
WordPiece provides better optimization for language modeling tasks.
SentencePiece offers flexibility and works well for multilingual and raw text processing.
In practice, the choice of tokenizer often depends on the architecture of the model and the characteristics of the dataset.
Conclusion
Tokenization plays a critical role in how AI systems process and understand language. By converting text into tokens, machine learning models can analyze patterns, generate predictions, and produce human-like responses.
Techniques such as Byte Pair Encoding, WordPiece, and SentencePiece have revolutionized NLP by enabling efficient subword tokenization. These methods reduce vocabulary complexity while improving the model's ability to understand language structures.
As AI continues to evolve, tokenization will remain a foundational component in building powerful and scalable natural language processing systems.

