With the explosion of digital content, managing and analyzing text data has become a critical challenge. Text classification—an essential task in Natural Language Processing (NLP)—helps automatically categorize text into predefined labels, making it easier to organize, filter, and analyze large volumes of information. From spam detection in emails to sentiment analysis on social media, text classification is everywhere.
This blog explores the core techniques used in text classification and their real-world applications across industries.
What is Text Classification?
Text classification is the process of assigning categories or tags to text based on its content. It leverages machine learning and NLP to automate what would otherwise be a time-consuming manual task.
Some popular examples include:
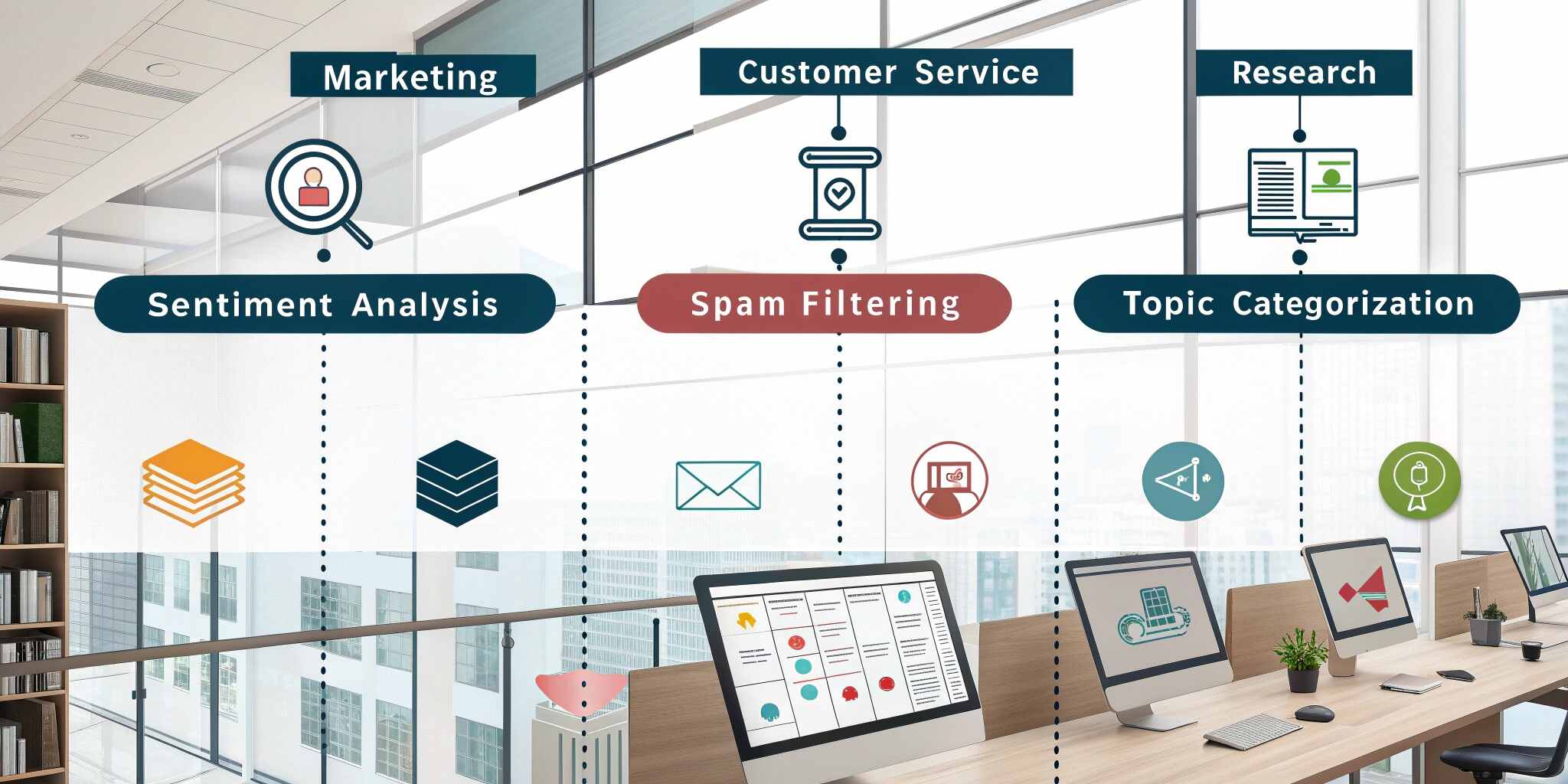
- Marking emails as spam or not spam.
- Categorizing customer reviews as positive, neutral, or negative.
- Routing customer support queries to the right department.
Techniques in Text Classification
- Rule-Based Approaches
- Early systems relied on hand-crafted rules like keyword matching and regular expressions. While simple, they lack scalability and adaptability.
- Traditional Machine Learning Algorithms
- Naïve Bayes: Based on Bayes’ theorem, it’s fast and effective for text classification tasks like spam detection.
- Support Vector Machines (SVM): Finds the optimal decision boundary for classification. Great for high-dimensional text data.
- Logistic Regression: Widely used for binary classification tasks.
- These models rely heavily on feature engineering, often using Bag-of-Words or TF-IDF to represent text.
Deep Learning Techniques
- Convolutional Neural Networks (CNNs): Capture local word patterns useful in sentiment analysis.
- Recurrent Neural Networks (RNNs) and LSTMs: Model sequential dependencies in text, making them ideal for contextual analysis.
- Transformers and Pre-Trained Models
- BERT (Bidirectional Encoder Representations from Transformers) and GPT-based models have revolutionized text classification. They understand context more effectively than traditional models and can be fine-tuned for specific tasks.
- These models eliminate the need for extensive manual feature engineering.
- Unsupervised & Semi-Supervised Techniques
- Topic Modeling (LDA, NMF): Groups text into topics without labeled data.
- Self-training and Transfer Learning: Allow effective use of limited labeled datasets.
Use Cases of Text Classification
- Spam Detection
- One of the earliest applications of text classification, spam filters use algorithms like Naïve Bayes to block unwanted emails while letting genuine messages through.
- Sentiment Analysis
- Businesses use sentiment analysis to understand customer opinions on products, services, or brands. Social media monitoring platforms leverage this technique to track brand reputation.
- Customer Support Automation
- AI-powered chatbots and support systems classify queries into categories, such as billing, technical support, or account issues, and route them to the right department.
- News Categorization
- News outlets classify articles into categories such as sports, politics, or entertainment, enabling better content organization and personalized recommendations.
- Healthcare
- Text classification helps process medical records, categorize patient notes, and even detect early signs of diseases through clinical text mining.
- E-commerce
- Online retailers classify product reviews by sentiment and categorize product descriptions for improved search and recommendation engines.
- Legal Industry
- Large volumes of legal documents can be automatically classified into contracts, case laws, or compliance documents for faster retrieval and analysis.
Challenges in Text Classification
- Ambiguity in Language: Words may carry different meanings depending on context.
- Data Imbalance: Some classes may have fewer examples, leading to biased models.
- Domain-Specific Vocabulary: Models trained on general datasets may perform poorly in specialized domains like law or medicine.
- Scalability: Handling billions of text documents efficiently requires robust infrastructure.
Future of Text Classification
With advances in transformers and generative AI, text classification will continue to evolve. We can expect few-shot and zero-shot learning models to become mainstream, enabling powerful classification with minimal labeled data. Integration with multimodal AI will also allow combining text with images, voice, and video for richer insights.
Conclusion
Text classification is the backbone of modern NLP applications, driving innovation in industries from healthcare to e-commerce. By leveraging machine learning, deep learning, and transformer-based models, organizations can automate complex tasks, enhance decision-making, and deliver better user experiences.

