Transformer architectures have revolutionized artificial intelligence, powering everything from language models and recommendation systems to image generation and autonomous decision-making. As organizations continue to build increasingly powerful AI systems, one of the most important architectural decisions involves choosing between dense and sparse transformer models.
Both approaches offer unique advantages and challenges. Dense models have traditionally dominated AI development due to their simplicity and effectiveness, while sparse models have emerged as a promising solution for scaling AI systems efficiently. Understanding the trade-offs between these architectures is critical for developers, researchers, and organizations investing in next-generation AI applications.
Understanding Transformer Models
Transformers are deep learning architectures designed to process and understand sequential data. They use self-attention mechanisms to identify relationships between different parts of the input and generate meaningful outputs.
Modern AI systems such as language models, chatbots, search engines, and content generation platforms rely heavily on transformer architectures because they can learn complex patterns from massive datasets.
As model sizes continue to grow from millions to billions—and even trillions—of parameters, computational efficiency has become a major challenge.
This challenge has driven the evolution of sparse transformer architectures.
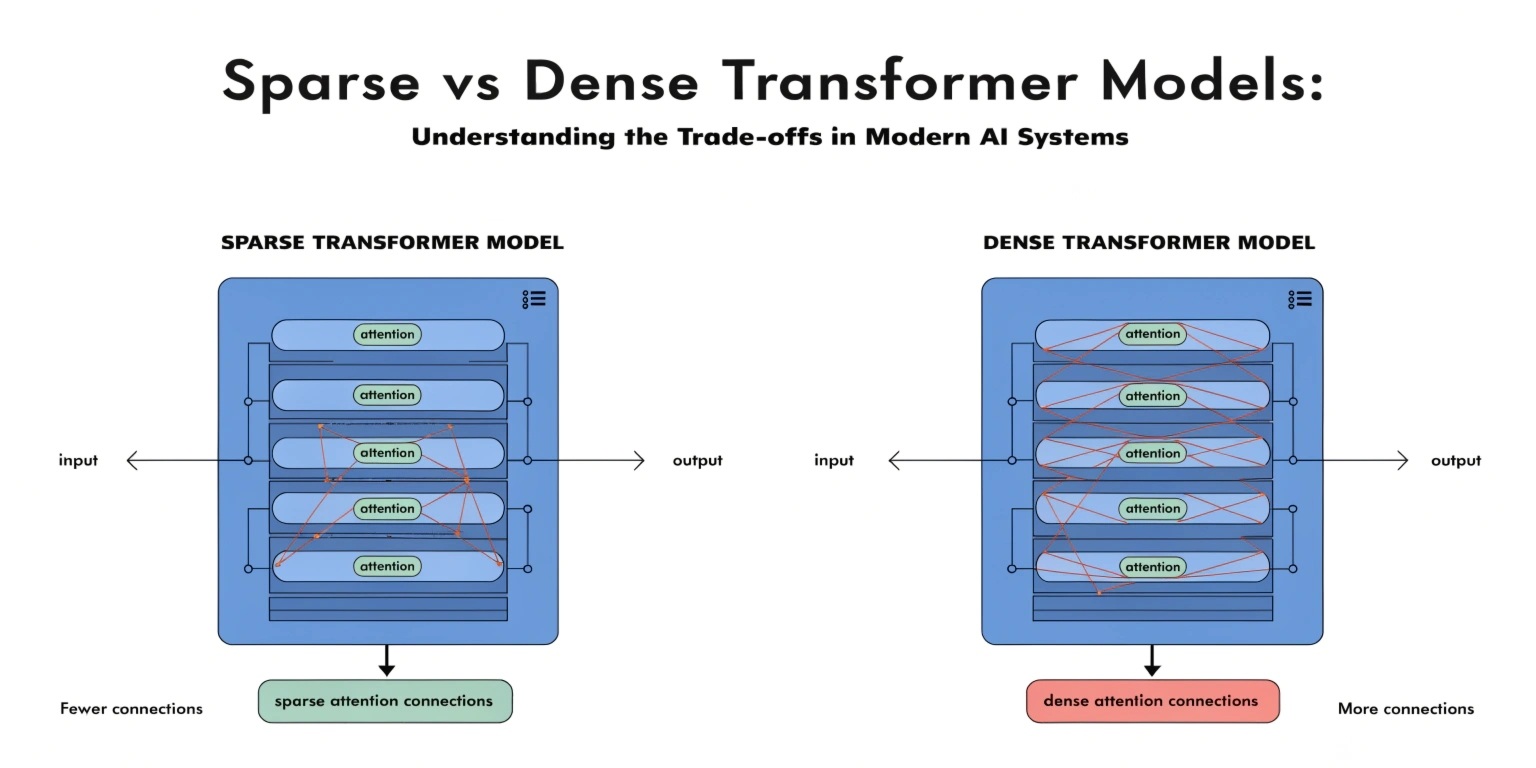
What Are Dense Transformer Models?
Dense transformer models activate every parameter during both training and inference.
When a user submits a query, the entire neural network participates in processing the request. Every layer and parameter contributes to generating the final output.
Examples of dense models include many traditional transformer architectures used in natural language processing and computer vision.
Advantages of Dense Models
Simpler Architecture
Dense models are easier to design, train, and deploy because all parameters participate uniformly.
Predictable Performance
Every inference follows the same computational path, making optimization more straightforward.
Strong Generalization
Since all parameters are updated during training, dense models often develop robust representations across multiple tasks.
Mature Tooling
Most deep learning frameworks are optimized for dense architectures, providing extensive ecosystem support.
Limitations of Dense Models
- High computational costs
- Increased energy consumption
- Expensive inference operations
- Memory-intensive deployments
- Scaling challenges for trillion-parameter models
As models become larger, these limitations become increasingly significant.
What Are Sparse Transformer Models?
Sparse transformer models activate only a subset of parameters for each input.
Instead of utilizing the entire network, specialized routing mechanisms determine which portions of the model should process a specific request.
One of the most popular implementations of sparsity is the Mixture of Experts (MoE) architecture.
In MoE systems:
- Multiple expert networks exist within the model.
- A routing mechanism selects relevant experts.
- Only selected experts perform computations.
- Unused experts remain inactive.
As a result, models can contain hundreds of billions or even trillions of parameters while requiring significantly less computation per query.
Advantages of Sparse Models
Improved Computational Efficiency
Only a fraction of parameters are activated during inference, reducing processing requirements.
Lower Operational Costs
Reduced computation translates into lower infrastructure and cloud expenses.
Greater Scalability
Organizations can build much larger models without proportional increases in inference costs.
Specialized Knowledge
Different experts can learn domain-specific skills, improving performance on diverse tasks.
Faster Inference for Large Models
Sparse architectures often achieve higher parameter counts while maintaining manageable response times.
Challenges of Sparse Models
Despite their advantages, sparse architectures introduce new complexities.
Routing Complexity
Expert selection mechanisms must accurately determine which experts should process each request.
Load Balancing Issues
Certain experts may become overloaded while others remain underutilized.
Training Instability
Sparse models can be more difficult to train effectively than dense counterparts.
Infrastructure Requirements
Distributed expert systems often require sophisticated hardware and networking configurations.
Debugging Difficulties
Understanding why a specific expert was selected can complicate model monitoring and optimization.
Dense vs Sparse: Key Trade-offs
Computational Cost
Dense models require computation across all parameters, resulting in higher costs.
Sparse models reduce active computations significantly.
Winner: Sparse Models
Simplicity
Dense architectures are easier to implement and maintain.
Winner: Dense Models
Scalability
Sparse systems enable parameter growth without linear increases in computation.
Winner: Sparse Models
Training Stability
Dense models generally exhibit more predictable training behavior.
Winner: Dense Models
Resource Efficiency
Sparse architectures make better use of computational resources.
Winner: Sparse Models
Ecosystem Support
Dense models currently enjoy broader industry support and tooling.
Winner: Dense Models
Real-World Applications
Dense Transformers
Dense architectures are commonly used in:
- Text classification
- Sentiment analysis
- Machine translation
- Computer vision tasks
- Recommendation engines
Their reliability makes them suitable for many production workloads.
Sparse Transformers
Sparse architectures are increasingly adopted for:
- Large Language Models (LLMs)
- Enterprise AI assistants
- Multimodal AI systems
- Cloud-scale AI services
- High-performance generative AI applications
These environments benefit significantly from improved efficiency and scalability.
The Future of Transformer Architectures
As AI continues to scale, sparse architectures are expected to play a larger role in reducing computational bottlenecks.
Several emerging trends are shaping the future:
Advanced Mixture of Experts Models
More intelligent routing systems will improve expert utilization and performance.
Hybrid Architectures
Future systems may combine dense and sparse components to achieve optimal efficiency.
Dynamic Computation
Models will increasingly allocate resources based on task complexity.
AI Hardware Optimization
Specialized processors are being developed to support sparse computation patterns more effectively.
Trillion-Parameter Models
Sparse architectures will likely become essential for training and deploying next-generation AI systems.
Conclusion
The choice between sparse and dense transformer models ultimately depends on the goals, resources, and scale of an AI project. Dense models offer simplicity, stability, and mature ecosystem support, making them ideal for many traditional machine learning applications.
Sparse models, however, provide a compelling path toward larger, more efficient AI systems by activating only the necessary portions of the network. As organizations seek to build increasingly powerful and cost-effective AI solutions, sparse architectures are becoming a critical component of modern machine learning infrastructure.
Understanding the strengths and limitations of both approaches enables businesses and developers to make informed decisions when designing the next generation of intelligent applications.

