Deep neural networks have revolutionized artificial intelligence by enabling machines to perform complex tasks such as image recognition, natural language processing, recommendation systems, and autonomous driving. However, as AI models become more sophisticated, they also become larger and computationally expensive. Modern neural networks often contain millions or even billions of parameters, requiring significant processing power, memory, and energy consumption.
To solve these challenges, researchers and engineers use pruning strategies to optimize neural networks without sacrificing significant accuracy. Neural network pruning removes unnecessary or less important parameters from a trained model, resulting in smaller, faster, and more efficient AI systems.
Pruning has become a critical optimization technique in deep learning, especially for deploying AI models on edge devices, mobile applications, IoT systems, and real-time environments where computational resources are limited.
What is Neural Network Pruning?
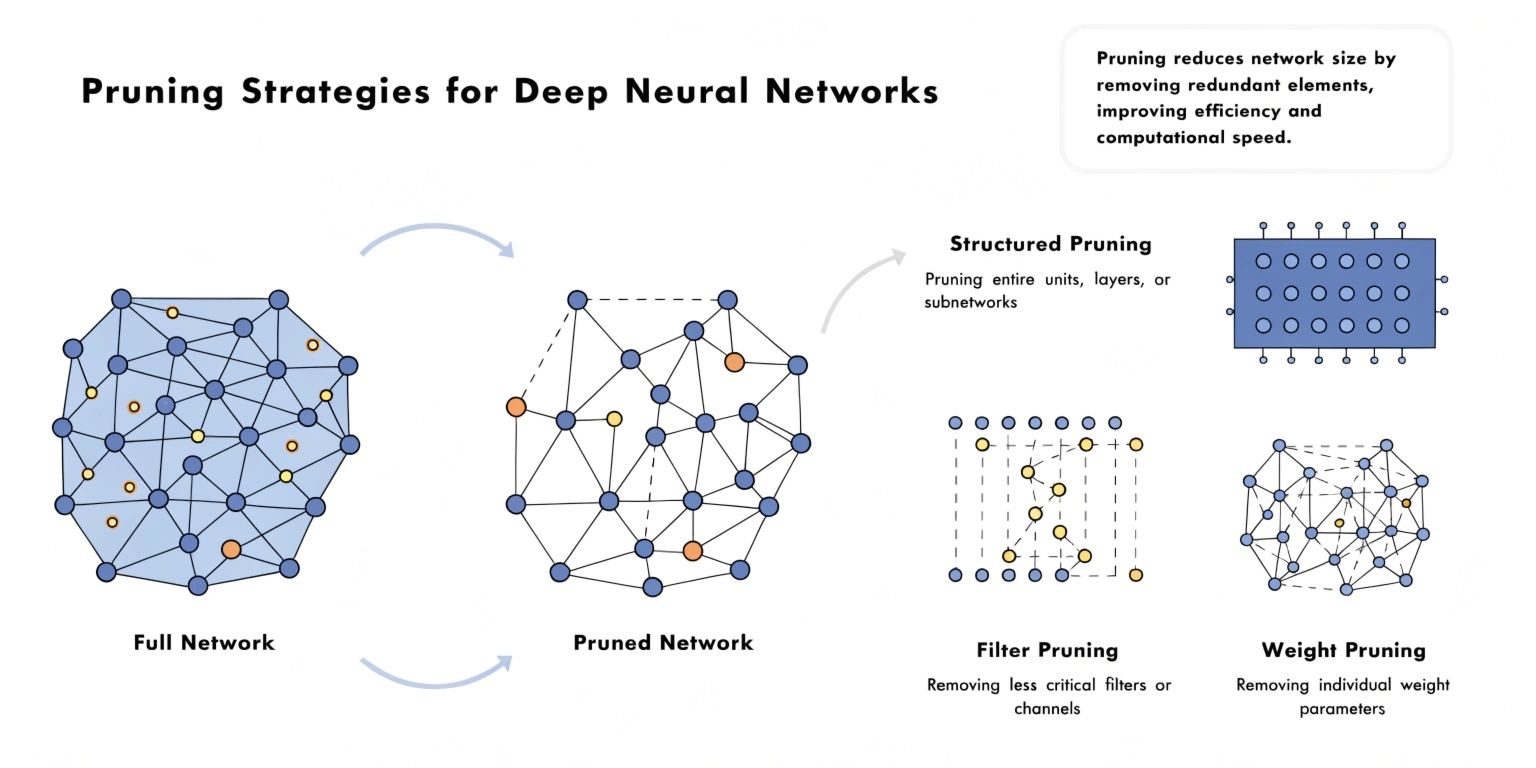
Neural network pruning is the process of reducing the size and complexity of a deep learning model by eliminating redundant neurons, connections, or weights. The goal is to create a lightweight model that maintains acceptable performance while improving efficiency.
Deep neural networks are often over-parameterized, meaning many weights contribute very little to the final prediction accuracy. Pruning identifies these low-importance parameters and removes them from the network.
The benefits include:
- Reduced memory usage
- Faster inference speed
- Lower energy consumption
- Improved scalability
- Better deployment on edge devices
Pruning is especially useful in industries where latency and hardware efficiency are critical.
Why Pruning is Important in Deep Learning
Model Compression
Large AI models consume extensive storage space. Pruning significantly reduces model size, making deployment easier.
Faster Inference
Pruned models require fewer computations, enabling quicker predictions and real-time processing.
Lower Hardware Requirements
Optimized models can run efficiently on smartphones, embedded systems, and IoT devices.
Reduced Energy Consumption
Efficient neural networks reduce GPU and CPU workload, improving sustainability and battery performance.
Scalability for Production Systems
Cloud-based AI services can serve more users with fewer computational resources.
Types of Pruning Strategies
1. Unstructured Pruning
Unstructured pruning removes individual weights based on importance scores. Typically, weights with the smallest magnitudes are removed because they contribute less to model performance.
Advantages:
- High compression rates
- Flexible optimization
Disadvantages:
- Sparse matrices may require specialized hardware for efficiency gains
This approach is common in research-focused AI optimization.
2. Structured Pruning
Structured pruning removes entire:
- Neurons
- Channels
- Filters
- Layers
Unlike unstructured pruning, structured pruning creates hardware-friendly architectures that are easier to accelerate on GPUs and CPUs.
Advantages:
- Better hardware compatibility
- Faster real-world inference
Disadvantages:
- May slightly reduce accuracy if aggressive pruning is applied
Structured pruning is widely used in production environments.
3. Magnitude-Based Pruning
This is one of the simplest pruning methods. Parameters with small weight magnitudes are removed after training.
Process:
- Train the model
- Identify low-magnitude weights
- Remove selected weights
- Fine-tune the model
This method is computationally efficient and widely adopted.
4. Iterative Pruning
Instead of pruning a large portion at once, iterative pruning gradually removes parameters over multiple training cycles.
Benefits:
- Better accuracy retention
- More stable optimization
Iterative pruning is commonly used in advanced AI systems where performance is critical.
5. Dynamic Pruning
Dynamic pruning adapts during runtime by activating only important parts of the neural network for specific tasks.
This approach improves:
- Energy efficiency
- Adaptive computation
- Real-time AI optimization
Dynamic pruning is increasingly important for edge AI and mobile AI applications.
Popular Pruning Techniques
Weight Pruning
Removes less important individual weights.
Filter Pruning
Removes convolutional filters in CNN architectures.
Neuron Pruning
Eliminates unnecessary neurons in hidden layers.
Layer Pruning
Removes entire layers from deep architectures.
Attention Head Pruning
Used in transformer models to remove less important attention mechanisms.
Challenges in Neural Network Pruning
Accuracy Loss
Aggressive pruning can reduce model performance and prediction quality.
Retraining Complexity
Pruned models often require fine-tuning or retraining to recover lost accuracy.
Hardware Limitations
Sparse models may not achieve expected acceleration without optimized hardware support.
Hyperparameter Tuning
Determining the ideal pruning ratio requires experimentation and optimization.
Applications of Pruned Neural Networks
Mobile AI Applications
Smartphone AI assistants and image recognition systems rely on lightweight models.
Autonomous Vehicles
Pruned models improve real-time decision-making efficiency.
Edge Computing
IoT devices require optimized AI models with low computational demands.
Healthcare AI
Medical imaging systems benefit from faster AI inference.
Natural Language Processing
Transformer models use pruning to reduce computational overhead.
Pruning and Modern AI Trends
The rise of large language models and generative AI has increased the need for efficient model optimization. AI researchers are combining pruning with:
- Quantization
- Knowledge distillation
- Low-rank factorization
- Sparse training
These hybrid optimization approaches help organizations deploy powerful AI systems at lower infrastructure costs.
Future of Neural Network Pruning
Future pruning technologies are expected to include:
- AI-driven automated pruning
- Self-optimizing neural architectures
- Adaptive sparse computing
- Neuromorphic hardware integration
- Real-time pruning during inference
As AI systems continue growing in scale, pruning will become even more essential for sustainable and scalable artificial intelligence.
Conclusion
Pruning strategies for deep neural networks have become a fundamental part of modern AI optimization. By removing unnecessary parameters, pruning enables faster, smaller, and more efficient neural networks without significantly compromising performance.
From mobile AI applications to large-scale cloud systems, pruning helps organizations reduce computational costs, improve scalability, and deploy AI models more effectively. As artificial intelligence continues evolving, advanced pruning techniques will play a major role in shaping the future of efficient and accessible deep learning systems.ill remain an essential pillar of successful project management.

