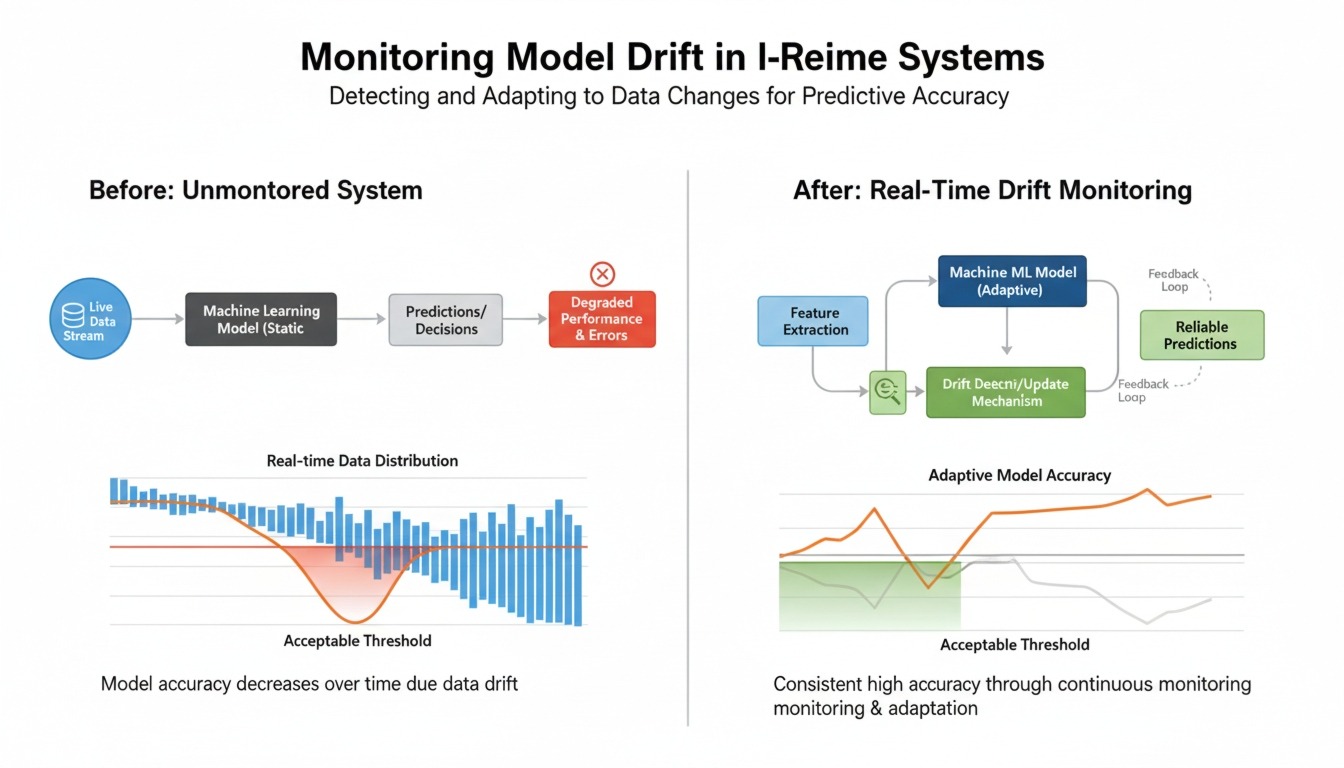
As organizations increasingly deploy machine learning models into real-time systems, maintaining their performance becomes a significant challenge. Unlike static environments, real-world data evolves over time. This evolution can cause models to lose accuracy—a phenomenon known as model drift.
Monitoring and addressing model drift is critical for ensuring that AI systems remain reliable, especially in applications like fraud detection, recommendation engines, and predictive analytics.
What is Model Drift?
Model drift occurs when a machine learning model’s performance degrades due to changes in data patterns or relationships over time. It typically falls into two main categories:
- Data Drift: Changes in the input data distribution
- Concept Drift: Changes in the relationship between inputs and outputs
For example, a recommendation system trained on last year’s user behavior may become less effective as user preferences evolve.
Why Real-Time Systems Are Vulnerable
Real-time systems process continuous streams of data, making them particularly susceptible to drift. Unlike batch systems, they must respond instantly, leaving little room for manual intervention.
Challenges include:
- Constantly changing data streams
- Lack of labeled data in real time
- Difficulty in tracking performance instantly
- High impact of errors on user experience
Without proper monitoring, drift can go unnoticed until it significantly impacts business outcomes.
Key Indicators of Model Drift
- Drop in Prediction Accuracy
- A sudden or gradual decline in accuracy is a strong signal of drift.
- Changes in Input Data Distribution
- Features may shift in range, variance, or frequency.
- Increase in Prediction Errors
- Higher error rates or unexpected outputs indicate model mismatch.
- Data Quality Issues
- Missing values, anomalies, or noise can contribute to drift.
Techniques for Detecting Drift
1. Statistical Methods
Use statistical tests such as Kolmogorov-Smirnov or Chi-square tests to compare current data with baseline distributions.
2. Monitoring Feature Distributions
Track key features over time to identify shifts in data patterns.
3. Model Performance Metrics
Continuously evaluate metrics like accuracy, precision, recall, or mean squared error.
4. Shadow Models
Deploy a secondary model alongside the primary one to compare outputs and detect inconsistencies.
Real-Time Monitoring Strategies
1. Data Pipeline Instrumentation
Integrate monitoring directly into data pipelines to capture real-time insights.
2. Alerts and Thresholds
Set thresholds for acceptable performance levels and trigger alerts when exceeded.
3. Streaming Analytics
Use stream processing frameworks to analyze incoming data and detect anomalies instantly.
4. Logging and Observability
Maintain detailed logs of inputs, outputs, and model decisions for analysis.
Mitigation Strategies for Model Drift
1. Continuous Retraining
Regularly retrain models using fresh data to adapt to new patterns.
2. Online Learning
Implement models that can learn incrementally from new data in real time.
3. Data Validation Pipelines
Ensure incoming data meets quality standards before feeding it to models.
4. Model Versioning
Maintain multiple versions of models to quickly roll back if performance drops.
Best Practices for MLOps Teams
- Automate Monitoring: Reduce manual effort with automated tools
- Define Clear Metrics: Align monitoring with business goals
- Use A/B Testing: Compare model versions in production
- Ensure Scalability: Design systems that handle high data volumes
- Maintain Transparency: Keep stakeholders informed about model performance
Tools and Technologies
Several tools can help monitor model drift effectively:
- Model monitoring platforms (e.g., Evidently, WhyLabs)
- Data streaming tools (e.g., Apache Kafka)
- Visualization dashboards (e.g., Grafana)
- Cloud-based ML services with built-in monitoring
Choosing the right combination depends on system complexity and scale.
Conclusion
Model drift is an inevitable challenge in real-time machine learning systems. Ignoring it can lead to inaccurate predictions, poor user experiences, and business losses.
By implementing robust monitoring systems, leveraging statistical detection techniques, and adopting continuous learning strategies, organizations can ensure their AI models remain accurate and reliable over time.
In a world driven by real-time data, proactive drift management is not just a best practice—it is a necessity for sustainable AI success.