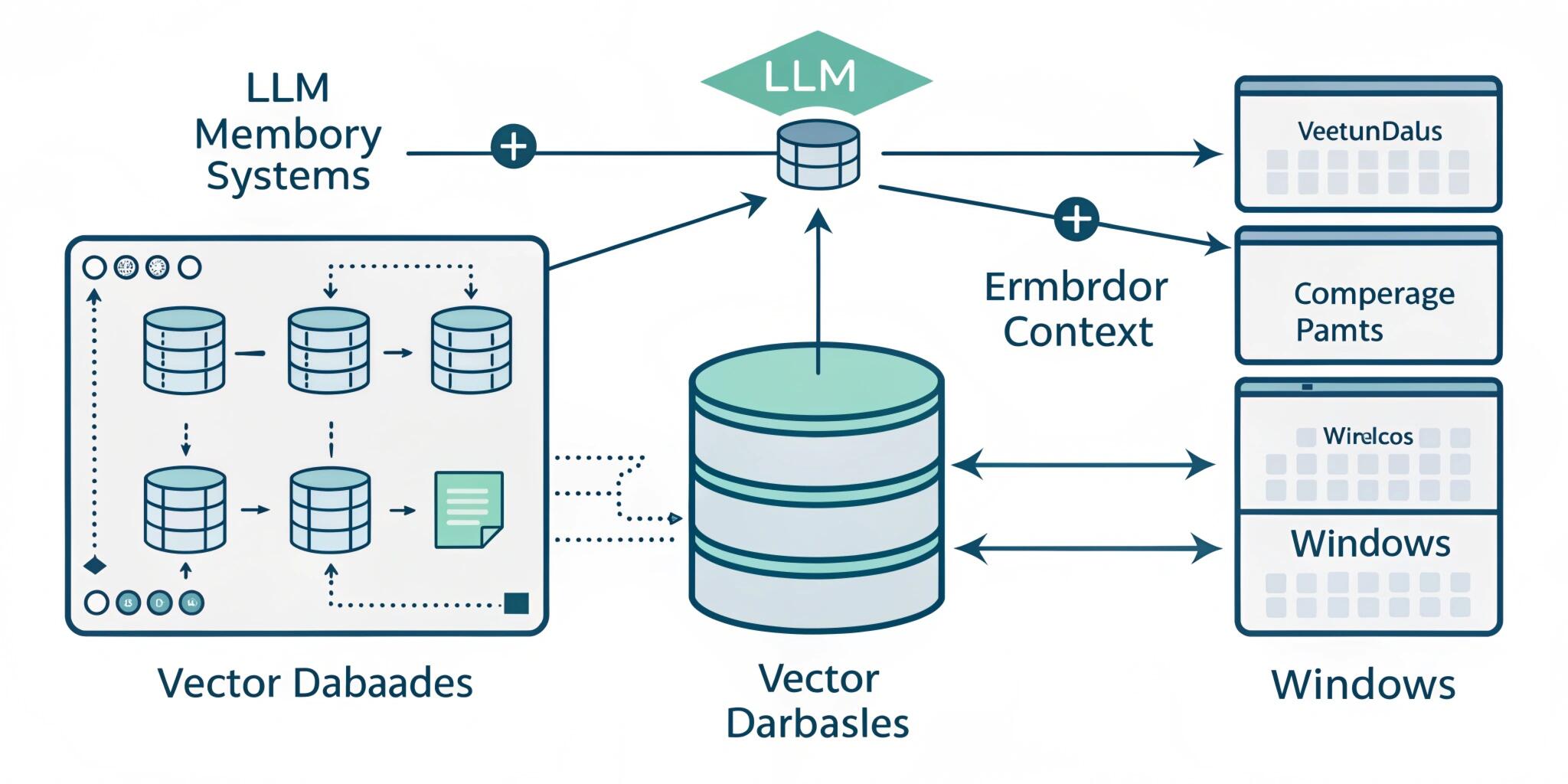
Large Language Models (LLMs) like ChatGPT, Claude, and other AI assistants often appear to remember conversations, preferences, and knowledge. However, in reality, LLMs do not have memory in the traditional sense. They don’t store facts in a database internally, nor do they permanently remember your past chats. Instead, they rely on a clever architecture combining context windows, embeddings, and vector databases to simulate memory.
This system is the foundation of modern AI chatbots and enterprise knowledge assistants.
Why LLMs Need External Memory
An LLM is essentially a probability engine trained on massive datasets. When you ask a question, the model predicts the most likely next word based on patterns learned during training.
But there is a limitation:
LLMs only “see” the information included in the current prompt.
If a company builds a chatbot for customer support, the model does not automatically know:
- Company policies
- Internal documents
- User purchase history
- Previous tickets
To solve this, developers build LLM memory systems using Retrieval-Augmented Generation (RAG).
Context Window: The Short-Term Memory
The context window is the amount of text the model can read at one time. It is measured in tokens (not words). A token may be a word, part of a word, or punctuation.
For example:
- “Artificial Intelligence” ≈ 2–3 tokens
Modern models can handle thousands or even hundreds of thousands of tokens, but the limit still exists. Once the conversation becomes longer than the context window, the model “forgets” earlier parts.
This works like human short-term memory.
The model only remembers what is currently visible in the prompt.
Because of this limitation, simply sending entire documents every time would be inefficient and expensive. That’s where embeddings and vector databases come in.
Embeddings: Turning Text into Numbers
Computers do not understand text the way humans do. To make information searchable, AI converts text into embeddings.
An embedding is a list of numbers (a vector) representing the meaning of a sentence.
Example:
“Car” and “Vehicle”
→ Different words
→ Very similar embeddings
“Car” and “Banana”
→ Very different embeddings
This means embeddings capture semantic meaning, not just keywords.
This is why modern AI search works even when users don’t type exact phrases.
Instead of matching text →
the system matches meaning.
Vector Databases: The Long-Term Memory
Once text is converted into embeddings, it is stored in a vector database.
Unlike traditional databases (SQL) that search by exact value, vector databases search by similarity. They find the closest meaning using mathematical distance (cosine similarity).
Popular vector databases include:
- Pinecone
- FAISS
- Weaviate
- Milvus
- Chroma
When a user asks a question, the system:
- Converts the question into an embedding
- Searches the vector database
- Finds relevant documents
- Sends them into the LLM prompt
The LLM then generates an answer based only on retrieved knowledge.
This process is called semantic retrieval.
Retrieval-Augmented Generation (RAG)
RAG is the architecture that connects everything together.
Instead of relying only on training data, the LLM retrieves real information before answering.
Workflow:
User Question → Embedding → Vector Search → Relevant Documents → Added to Prompt → LLM Response
This is why enterprise AI assistants can:
- Answer HR policy questions
- Read PDFs
- Analyze contracts
- Support customers
The model is not remembering —
it is retrieving information in real time.
Why This Is Better Than Fine-Tuning
Many people assume you must retrain an AI model to teach it new information. That is expensive and slow.
RAG provides major advantages:
- No retraining required
- Works with live data
- Easy updates
- Lower cost
- Reduced hallucinations
Instead of retraining the model when a document changes, you simply update the vector database.
Real-World Example
Imagine a company uploads 5,000 internal documents.
Without RAG:
The AI gives generic answers.
With RAG:
The system searches internal files, retrieves relevant paragraphs, inserts them into the prompt, and the AI answers accurately.
This is how modern AI helpdesk chatbots and knowledge assistants work.
The Future of AI Memory
Future AI systems will combine:
- Long context windows
- Persistent memory stores
- Personalization layers
- Real-time data streaming
We are moving toward AI assistants that act less like tools and more like collaborators. However, technically they still don’t “remember” — they retrieve, rank, and reason.
Understanding this architecture is crucial for developers building modern AI applications. LLM memory systems are not magic; they are an intelligent integration of mathematics, databases, and language modeling.

