In today’s AI-driven world, search is no longer about matching keywords—it’s about understanding meaning. This is where embeddings come into play. Embeddings are the backbone of semantic search, enabling machines to interpret context, intent, and relationships between words, sentences, and even images.
But what exactly are embeddings, and what math powers them? Let’s break it down in a simple and practical way.
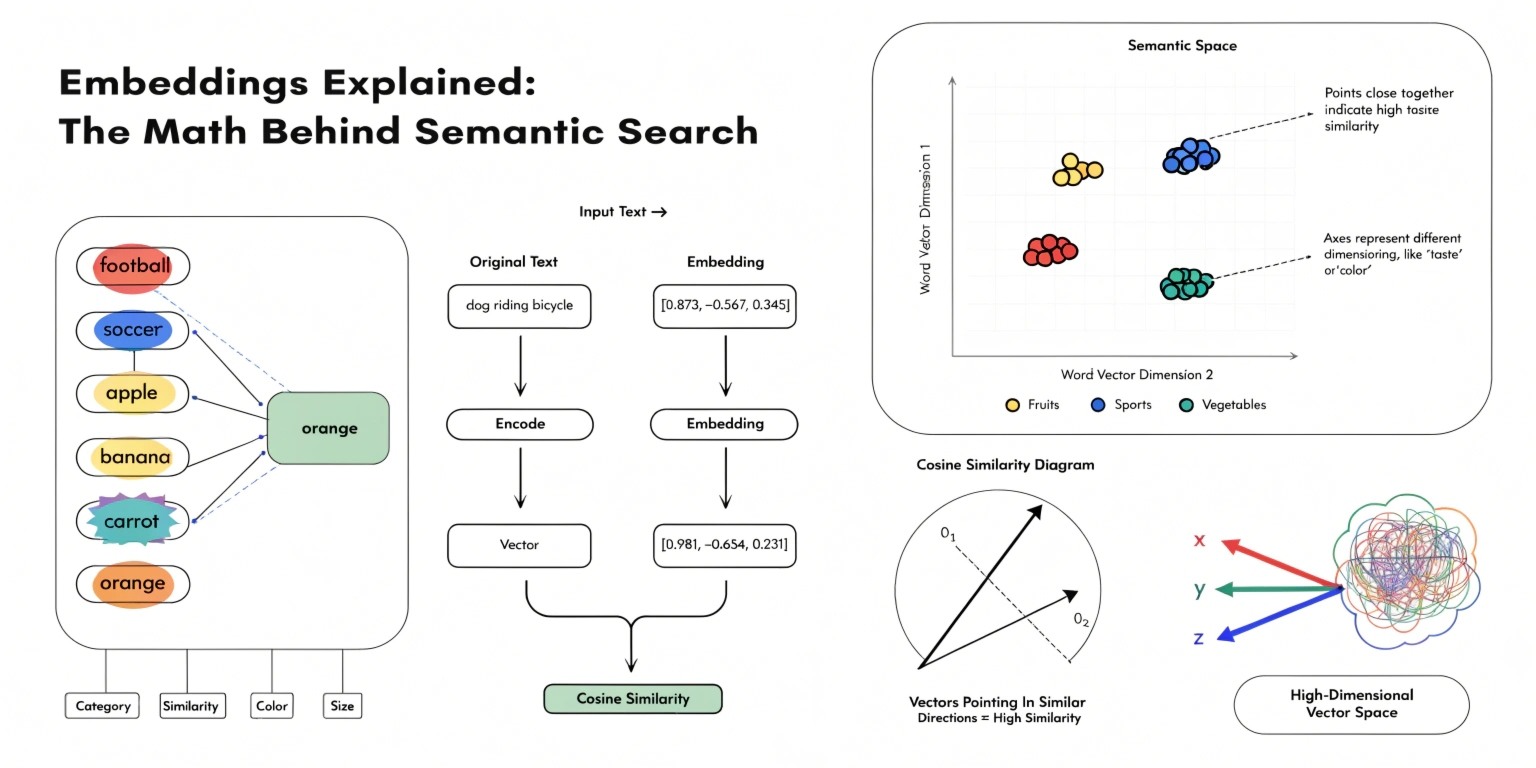
What Are Embeddings?
Embeddings are numerical representations of data—typically text—converted into vectors in a high-dimensional space. Instead of treating words as isolated tokens, embeddings map them into positions where similar meanings are placed closer together.
For example:
- "King" and "Queen" will be close
- "Apple" (fruit) and "Banana" will cluster
- "Apple" (company) may be closer to "Microsoft"
This transformation allows machines to "understand" relationships rather than just exact matches.
From Words to Vectors
Each word or sentence is converted into a vector like this:
"cat" → [0.21, -0.45, 0.67, ..., 0.12]
"dog" → [0.19, -0.40, 0.70, ..., 0.15]
These vectors may have hundreds or thousands of dimensions depending on the model.
The key idea:
Similar meanings → Similar vector directions
The Core Math: Measuring Similarity
To determine how similar two pieces of text are, we use mathematical distance or similarity measures. The most common one is cosine similarity.
Here’s the formula:
cos(θ)=A⋅B∥A∥∥B∥\cos(\theta)=\frac{A \cdot B}{\|A\|\|B\|}cos(θ)=∥A∥∥B∥A⋅B
Where:
- A · B = dot product of two vectors
- ||A||, ||B|| = magnitudes of vectors
- θ (theta) = angle between vectors
Why Cosine Similarity Works
Cosine similarity measures the angle between vectors, not their length. This makes it ideal for text comparison because:
- It ignores sentence length differences
- Focuses on direction (meaning)
- Produces values between -1 and 1
Example:
- 1 → exactly similar
- 0 → unrelated
- -1 → opposite meaning
So, even if two sentences use different words but share meaning, cosine similarity will detect that.
High-Dimensional Vector Space
Embeddings exist in high-dimensional spaces (e.g., 512D, 768D, 1536D). While humans can’t visualize this, mathematically it allows:
- Rich semantic representation
- Contextual understanding
- Better clustering of ideas
Think of it like a map where every word or sentence has coordinates, and similar meanings are neighbors.
How Semantic Search Uses Embeddings
Traditional search:
- Matches keywords
- Fails with synonyms or rephrased queries
Semantic search:
- Convert query into embedding
- Convert documents into embeddings
- Compare using cosine similarity
- Return closest matches
Example:
Query: “Best places to work remotely”
Results may include:
- “Top remote work-friendly cities”
- “Best locations for digital nomads”
Even without exact keyword matches, the system understands intent.
Types of Embeddings
- Word EmbeddingsExample: Word2Vec, GloVe
- Focus on individual words
- Sentence EmbeddingsCapture full sentence meaning
- Used in search and chatbots
- Contextual EmbeddingsGenerated by transformer models
- Same word can have different meanings depending on context
Real-World Applications
- Search Engines: Google-like semantic retrieval
- Chatbots: Understanding user intent
- Recommendation Systems: Suggesting similar products/content
- Document Clustering: Grouping similar texts
- Fraud Detection: Pattern recognition in transactions
Challenges in Embeddings
Despite their power, embeddings have limitations:
- High computational cost
- Storage requirements for vectors
- Bias in training data
- Difficulty interpreting dimensions
To address these, vector databases and optimized indexing methods like FAISS or HNSW are used.
Conclusion
Embeddings are a powerful way to represent meaning mathematically. By transforming text into vectors and using similarity measures like cosine similarity, machines can perform semantic search that feels intuitive and human-like.
Understanding the math behind embeddings gives you a strong foundation to build smarter AI systems—from search engines to recommendation platforms.

