As artificial intelligence models continue to grow in complexity and size, deploying them efficiently has become a major challenge for developers and businesses. Large Language Models (LLMs), deep learning systems, and transformer architectures often require massive computational resources, making them expensive and difficult to run on edge devices, mobile applications, and low-latency environments.
To solve this problem, AI engineers use model optimization techniques such as Distillation and Quantization. Both methods aim to reduce model size and improve performance, but they work differently and are suitable for different scenarios.
Understanding the differences between Distillation and Quantization is essential for AI developers, ML engineers, and businesses building scalable AI applications.
What is Model Distillation?
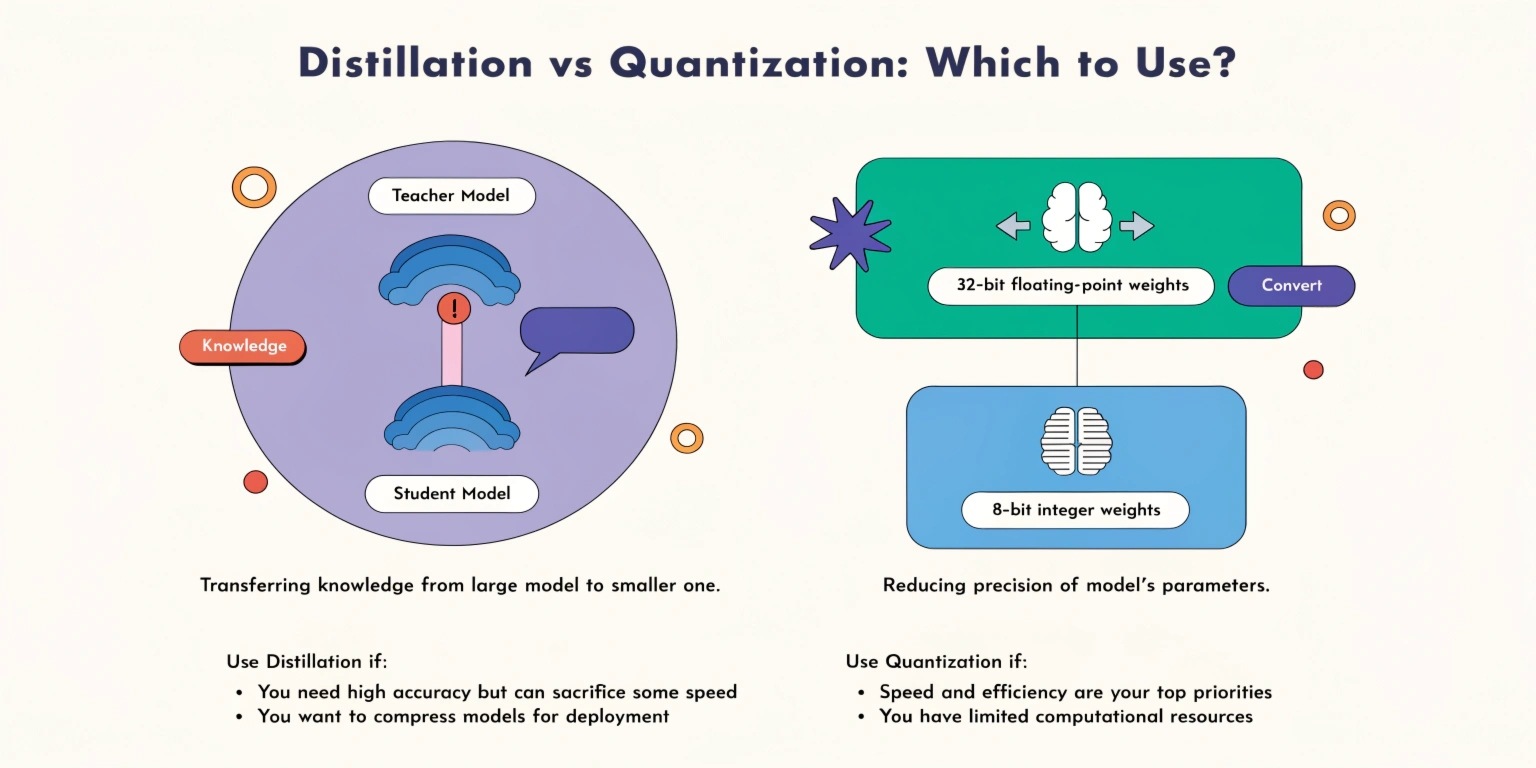
Model Distillation, also called Knowledge Distillation, is a process where a smaller “student” model learns from a larger and more powerful “teacher” model.
The teacher model transfers its learned knowledge to the student model so the smaller model can achieve similar performance with fewer parameters.
Distillation Concept
Student Model≈Teacher Model OutputStudent\ Model \approx Teacher\ Model\ OutputStudent Model≈Teacher Model Output
Instead of training directly from raw labels only, the student model learns from the probability distributions generated by the teacher model.
Benefits of Distillation
Smaller Model Size
Distilled models contain fewer parameters, making deployment easier.
Faster Inference
Reduced model complexity improves prediction speed.
Lower Hardware Requirements
Distilled models can run efficiently on mobile devices and edge hardware.
Better Generalization
In some cases, distilled models perform better than traditionally trained small models.
Limitations of Distillation
Additional Training Time
Distillation requires training both teacher and student models.
Accuracy Trade-Offs
The smaller model may lose some knowledge from the teacher.
Complex Implementation
Distillation pipelines can become technically challenging for large-scale systems.
What is Quantization?
Quantization reduces the numerical precision of model weights and computations. Instead of using high-precision floating-point values, quantized models use lower-bit representations such as INT8 or FP16.
Quantization Concept
32-bit Floating Point→8-bit Integer32\text{-bit Floating Point} \rightarrow 8\text{-bit Integer}32-bit Floating Point→8-bit Integer
This dramatically reduces memory usage and computational cost.
Types of Quantization
1. Post-Training Quantization
The model is quantized after training without retraining.
2. Quantization-Aware Training
The model is trained while considering low-precision arithmetic.
3. Dynamic Quantization
Weights are quantized dynamically during inference.
4. Static Quantization
Weights and activations are pre-quantized before deployment.
Benefits of Quantization
Reduced Memory Usage
Quantized models consume significantly less storage.
Faster AI Inference
Lower precision calculations improve processing speed.
Lower Power Consumption
Ideal for mobile and embedded AI systems.
Cost Optimization
Reduces cloud infrastructure and GPU costs.
Limitations of Quantization
Accuracy Reduction
Aggressive quantization may reduce prediction accuracy.
Hardware Compatibility
Some devices may not fully support specific quantization formats.
Optimization Complexity
Advanced quantization methods require careful tuning.
Distillation vs Quantization: Key Differences
FeatureDistillationQuantizationMain GoalCreate smaller intelligent modelsReduce computational precisionMethodKnowledge transferNumerical compressionAccuracy ImpactModerateLow to moderateTraining RequiredYesSometimesDeployment SpeedFasterMuch fasterHardware EfficiencyGoodExcellentBest Use CaseLightweight intelligent modelsHigh-speed inference systems
When Should You Use Distillation?
Distillation is ideal when:
- Maintaining model intelligence is critical
- Deploying AI on mobile applications
- Reducing model complexity while preserving reasoning ability
- Creating efficient chatbot or NLP systems
- Building lightweight transformer models
Example Use Cases
- AI virtual assistants
- Mobile NLP applications
- Recommendation systems
- Edge AI chatbots
Distillation is commonly used in transformer-based architectures and Large Language Models where retaining semantic understanding is important.
When Should You Use Quantization?
Quantization is best when:
- Low latency is the highest priority
- Hardware resources are limited
- Deploying AI on embedded systems
- Optimizing inference costs in cloud environments
- Running models on CPUs instead of GPUs
Example Use Cases
- Real-time AI inference
- IoT devices
- Autonomous systems
- Edge computing
- Computer vision applications
Quantization is especially popular in production environments where speed and scalability matter most.
Can Distillation and Quantization Be Used Together?
Yes. Modern AI systems often combine both techniques for maximum optimization.
Combined Optimization Pipeline
- Distill a large model into a smaller student model
- Quantize the distilled model for deployment
This approach creates:
- Smaller models
- Faster inference
- Reduced infrastructure costs
- Better deployment flexibility
Many advanced AI frameworks use hybrid optimization strategies to achieve enterprise-grade efficiency.
Role in Large Language Models (LLMs)
As LLMs become more expensive to deploy, optimization techniques are becoming essential.
Companies developing generative AI systems use:
- Distillation to create lightweight LLM variants
- Quantization to reduce GPU memory requirements
This allows businesses to deploy AI solutions on:
- Consumer devices
- Edge hardware
- Browser-based AI systems
- Cost-efficient cloud infrastructure
Optimization is now a critical component of scalable AI engineering.
Future of AI Model Optimization
The future of AI optimization will likely involve:
- Adaptive quantization
- Automated distillation pipelines
- Hardware-aware model compression
- Efficient transformer architectures
- AI inference acceleration chips
As AI adoption grows, businesses will increasingly prioritize efficient models over extremely large resource-intensive systems.
Conclusion
Distillation and Quantization are two powerful AI optimization techniques that help make machine learning models faster, smaller, and more deployable.
Distillation focuses on transferring intelligence from large models into compact versions while preserving accuracy and reasoning capabilities. Quantization focuses on reducing numerical precision to improve speed, efficiency, and scalability.
The best choice depends on your project goals:
- Choose Distillation when maintaining model intelligence matters most.
- Choose Quantization when speed, memory efficiency, and low latency are the priority.
- Combine both techniques for highly optimized production AI systems.
As AI applications continue expanding across industries, understanding these optimization methods will become increasingly important for developers, enterprises, and technology leaders.

