Introduction:-
As Artificial Intelligence continues to evolve, aligning models with human intent has become a critical challenge. Large Language Models (LLMs) like ChatGPT rely heavily on post-training techniques to ensure outputs are safe, relevant, and helpful. Two prominent approaches in this domain are Reinforcement Learning from Human Feedback (RLHF) and the newer Direct
Preference Optimization (DPO).
Understanding the difference between these two techniques is essential for developers and AI practitioners working on modern AI systems.
What is RLHF?
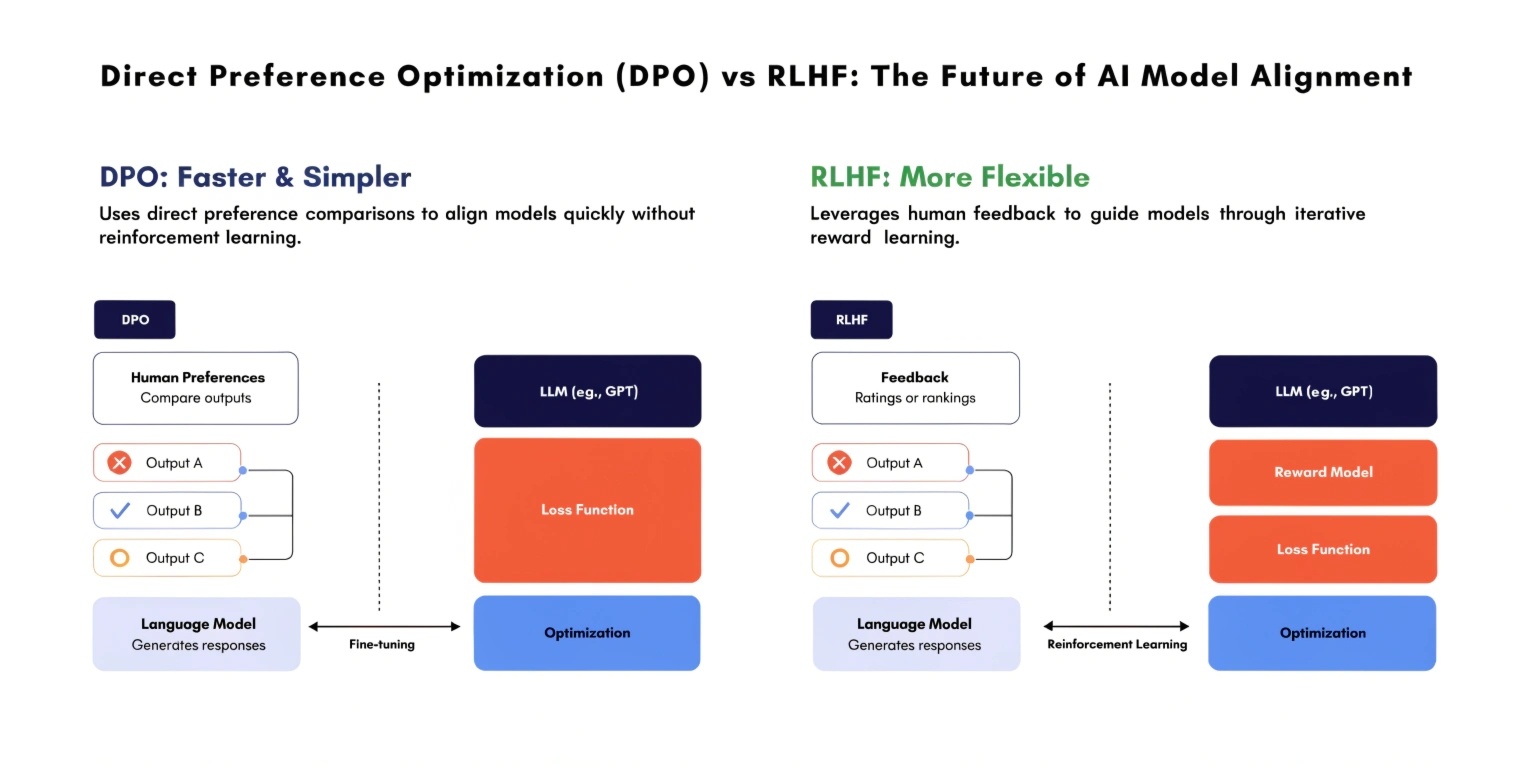
Reinforcement Learning from Human Feedback (RLHF) is a widely used technique for aligning AI models with human preferences. It involves three major steps:
- Pretraining the model on large datasets
- Collecting human feedback by ranking model outputs
- Training a reward model and optimizing the AI using reinforcement learning
In RLHF, the AI model learns to maximize a reward signal derived from human preferences. This reward model acts as a proxy for human judgment.
Advantages of RLHF
- Produces highly aligned and human-like responses
- Effective for complex tasks requiring nuanced understanding
- Proven success in production-level AI systems
Limitations of RLHF
- Complex training pipeline
- Requires separate reward model
- Computationally expensive
- Risk of reward hacking (model exploiting reward system)
What is Direct Preference Optimization (DPO)?
Direct Preference Optimization (DPO) is a newer and simpler alternative to RLHF. Instead of training a separate reward model, DPO directly optimizes the model using human preference data.
In DPO, the model is trained to prefer one response over another based on human feedback, without reinforcement learning loops.
Advantages of DPO
- Simpler implementation (no reward model required)
- More stable training process
- Reduced computational cost
- Eliminates reward hacking issues
Limitations of DPO
- Relatively new and less tested in large-scale systems
- May lack fine-grained control compared to RLHF
- Dependent on high-quality preference data
Key Differences Between DPO and RLHF
Feature RLHF DPO Training Approach Reinforcement Learning Supervised Optimization Reward Model Required Not Required Complexity High Low Stability Can be unstableMore stable Computational Cost High Lower Risk of Reward HackingYes No
Which One is Better?
The choice between DPO and RLHF depends on the use case.
- Use RLHF when:
- You need highly refined and controlled outputs
- You can afford complex infrastructure
- Your application requires deep alignment
- Use DPO when:
- You want faster and simpler training
- You aim for cost efficiency
- You prefer stable and scalable solutions
In many modern AI systems, DPO is gaining traction as a practical alternative due to its simplicity and efficiency.
Real-World Applications
Both RLHF and DPO are used in training large-scale AI systems such as:
- Chatbots and virtual assistants
- Content generation tools
- Code generation models
- Customer support automation
Companies are increasingly experimenting with DPO to streamline their AI pipelines while maintaining performance.
Future of AI Alignment
The future of AI alignment is moving toward simpler, more scalable solutions. While RLHF remains a gold standard, DPO represents a shift toward efficiency and practicality.
As AI models grow larger and more complex, reducing training overhead without compromising performance will be crucial. DPO may play a significant role in shaping next-generation AI systems.
Conclusion
Direct Preference Optimization (DPO) and Reinforcement Learning from Human Feedback (RLHF) are both powerful techniques for aligning AI models with human intent. While RLHF offers deep control and proven results, DPO provides a simpler, more efficient alternative.
For developers and organizations, the decision ultimately depends on balancing performance, complexity, and cost. As the AI landscape evolves, DPO is emerging as a strong contender in the future of model alignment.

