Large Language Models (LLMs) have become a central component of modern AI applications. From chatbots and virtual assistants to automated content generation and customer support systems, LLMs power many intelligent digital services.
However, running LLM-based applications can be expensive. Most AI providers charge based on token usage, meaning every input and output processed by the model contributes to operational costs.
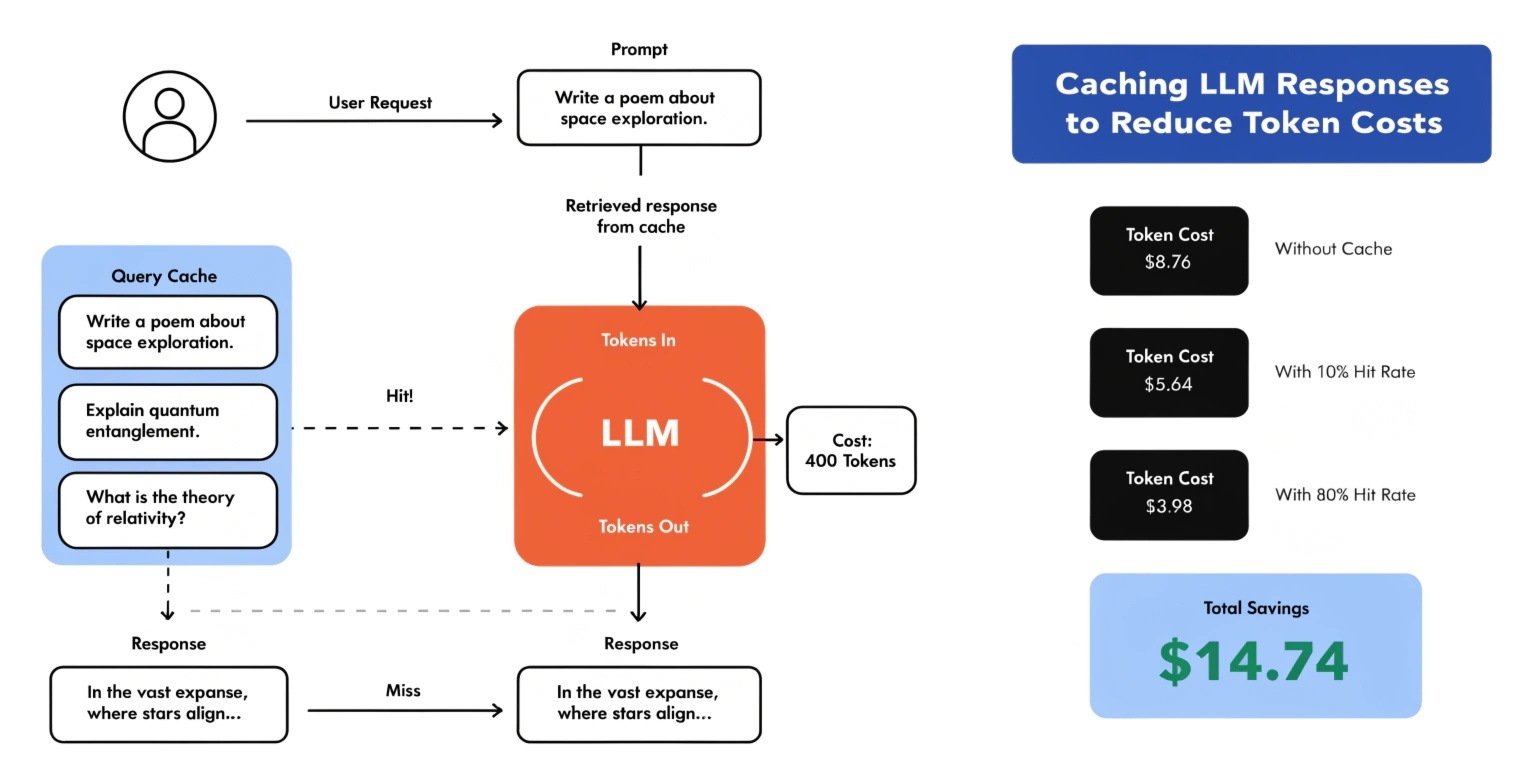
For applications that handle thousands or even millions of requests, these costs can grow rapidly. One effective strategy for controlling expenses is caching LLM responses.
Caching allows applications to store previously generated responses and reuse them when similar or identical queries appear again. This approach significantly reduces token usage while improving response speed.
Understanding Token Costs in LLM Applications
Tokens are the basic units used by language models to process text. A token may represent a word, part of a word, or punctuation.
When an application sends a request to an LLM, the cost typically depends on:
- Number of input tokens (prompt)
- Number of output tokens (generated response)
For example:
If an application processes:
- 500 input tokens
- 500 output tokens
Total tokens per request = 1000 tokens
For large-scale systems such as AI customer service platforms or search assistants, millions of tokens may be consumed daily. Without optimization strategies, operational costs can become unsustainable.
Caching helps reduce repeated requests to the model.
What is LLM Response Caching?
LLM response caching is the process of storing the output generated by a model for a specific prompt so that future identical or similar prompts can reuse the stored result.
Instead of calling the model again, the system retrieves the response directly from a cache.
Benefits of caching include:
- Lower API token usage
- Faster response times
- Reduced infrastructure load
- Improved scalability
This approach is particularly useful for applications where many users ask similar questions.
Common Use Cases for LLM Caching
Caching is highly effective in scenarios where queries repeat frequently.
1. Customer Support Chatbots
Users often ask similar questions such as:
- "What is your refund policy?"
- "How do I reset my password?"
Instead of generating a new response each time, the system can return a cached answer.
2. AI Knowledge Base Systems
Internal knowledge assistants used by companies often receive repeated queries about documentation or policies.
Caching common answers dramatically reduces token usage.
3. AI Content Generation Platforms
Content generation tools may produce repeated outputs for prompts such as:
- "Write a product description for a laptop"
- "Generate a blog outline for SEO"
Caching popular prompts helps optimize system efficiency.
Types of LLM Caching Strategies
There are several caching strategies developers use depending on application requirements.
1. Exact Prompt Matching
The simplest method is storing responses for exactly identical prompts.
If a prompt matches an existing cache key, the stored response is returned.
Example:
Prompt:
"What is cloud computing?"
If the same prompt appears again, the cached response is used.
This method is easy to implement but may miss similar queries with slightly different wording.
2. Semantic Caching
Semantic caching uses embeddings to identify prompts that are similar in meaning rather than identical in wording.
For example:
Prompt A:
"What is machine learning?"
Prompt B:
"Explain machine learning"
Both prompts have the same intent and could use the same cached response.
Semantic caching improves cache hit rates and reduces redundant LLM calls.
3. Partial Prompt Caching
In some cases, only parts of a prompt change.
For example:
"Write a product description for [Product Name]"
The template remains constant while the product name changes.
Caching reusable prompt components can reduce token usage significantly.
Tools Used for LLM Response Caching
Developers commonly use high-performance caching systems such as:
Redis
An in-memory database widely used for caching AI responses due to its extremely fast read and write speeds.
Vector Databases
Vector databases store embeddings and allow semantic search to retrieve similar prompts.
Edge Caching
AI responses can be cached at the edge using CDN infrastructure, reducing latency for global users.
Best Practices for Implementing LLM Caching
To maximize the benefits of caching, developers should follow several best practices.
Define Cache Expiration Policies
Some responses may become outdated. Implement TTL (time-to-live) rules to refresh cached responses periodically.
Normalize Prompts
Small differences such as capitalization or extra spaces may reduce cache efficiency. Normalizing prompts before caching helps improve cache hits.
Monitor Cache Performance
Track metrics such as:
- Cache hit rate
- Token savings
- Response latency
These insights help optimize the caching strategy.
Use Hybrid Strategies
Combining exact matching and semantic caching often produces the best results.
Challenges in LLM Response Caching
Despite its advantages, caching introduces certain challenges.
Responses generated by LLMs may depend on context, personalization, or time-sensitive information. Reusing cached responses without considering these factors could lead to inaccurate outputs.
Additionally, semantic caching systems require embedding models and vector search infrastructure, which adds complexity.
However, with careful implementation, these challenges can be managed effectively.
Conclusion
Caching LLM responses is one of the most effective strategies for reducing token costs and improving the performance of AI-powered applications. By storing previously generated responses and intelligently reusing them, developers can significantly reduce API usage while delivering faster responses to users.
As AI systems continue to scale, techniques such as prompt normalization, semantic caching, and hybrid cache architectures will become essential components of efficient AI infrastructure.
Organizations that implement smart caching strategies can build scalable, cost-efficient AI systems capable of handling large volumes of requests without excessive operational expenses.

