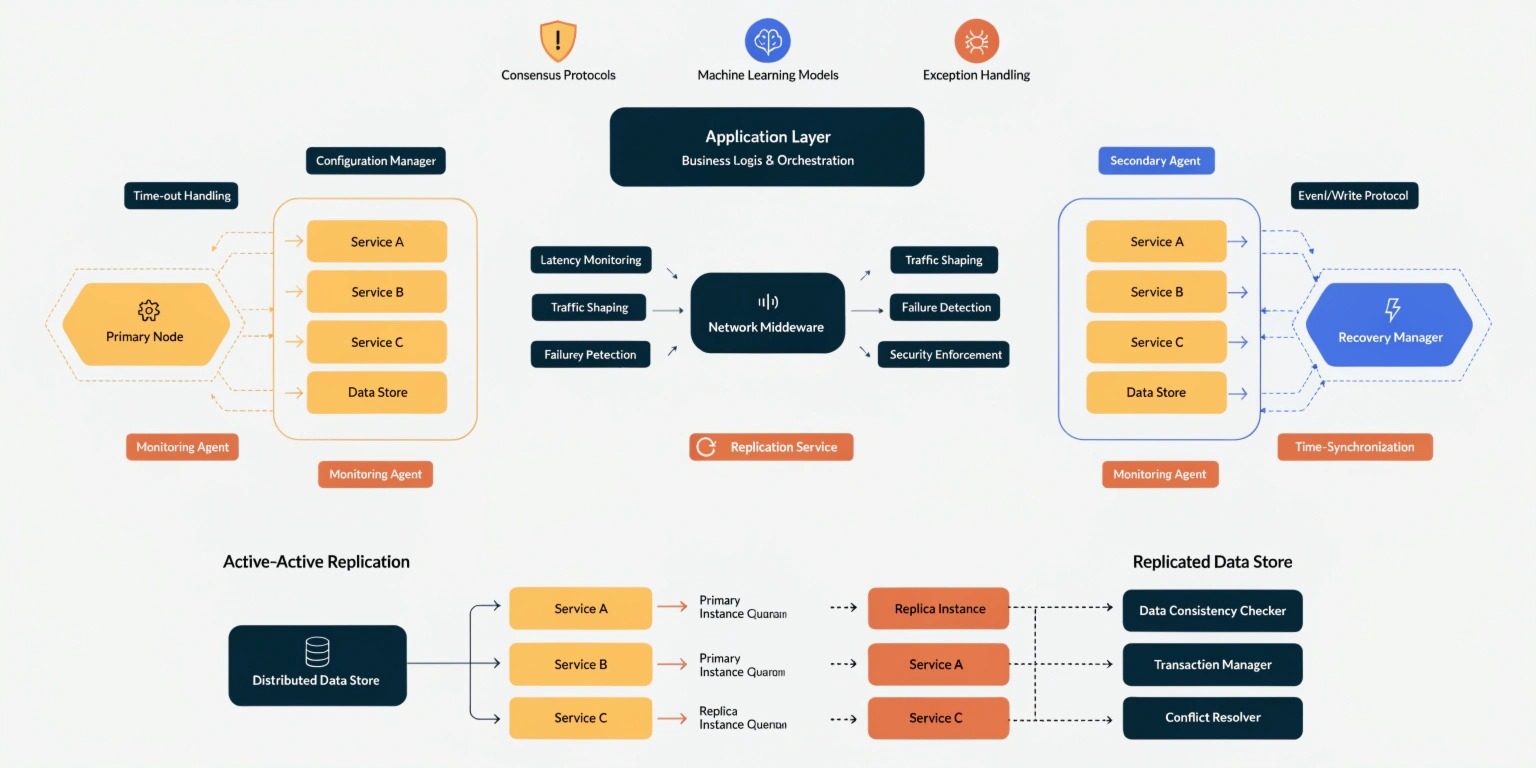
Modern applications rely heavily on distributed systems to support millions of users, handle large volumes of data, and deliver highly available services. However, distributing services across multiple servers, networks, and regions introduces a significant challenge: failures are inevitable.
Hardware crashes, network outages, software bugs, and service overloads can occur at any time. This is why building fault-tolerant distributed systems is a core requirement for modern software architecture.
Fault tolerance ensures that a system continues to operate even when components fail, minimizing downtime and maintaining reliability.
Understanding Fault Tolerance
Fault tolerance refers to a system's ability to continue functioning properly even when one or more components fail. Instead of preventing failures entirely—which is impossible—distributed systems are designed to detect, isolate, and recover from failures automatically.
A well-designed fault-tolerant system ensures:
- Minimal service disruption
- Automatic recovery mechanisms
- Data consistency and reliability
- High system availability
These characteristics are essential for services such as e-commerce platforms, banking systems, cloud services, and real-time communication platforms.
Why Distributed Systems Fail
Failures in distributed systems occur due to several factors.
Hardware Failures
Servers, disks, and network devices can crash unexpectedly. Even large cloud providers experience hardware failures regularly.
Network Failures
Network partitions, latency spikes, and packet loss can prevent services from communicating effectively.
Software Bugs
Complex distributed applications often contain subtle bugs that can cause services to crash or behave unpredictably.
Traffic Overload
Sudden traffic spikes can overwhelm servers, leading to degraded performance or outages.
Because these failures are unavoidable, systems must be built to handle them gracefully.
Core Principles of Fault-Tolerant Systems
Several architectural principles help create resilient distributed systems.
Redundancy
Redundancy involves duplicating critical components so that if one fails, another can take over.
Examples include:
- Multiple servers running the same service
- Replicated databases
- Backup network routes
Redundancy ensures that the failure of a single component does not bring down the entire system.
Replication
Replication involves storing copies of data across multiple nodes. This improves both reliability and availability.
There are two common replication models:
Synchronous replication
Ensures data consistency across nodes but may increase latency.
Asynchronous replication
Improves performance but may risk temporary data inconsistencies.
Choosing the right approach depends on the system's consistency requirements.
Failover Mechanisms
Failover allows systems to automatically switch to a backup component when the primary component fails.
Examples include:
- Database replicas taking over after primary failure
- Load balancers redirecting traffic to healthy servers
- Backup services activating during outages
Automatic failover significantly reduces downtime.
Load Balancing for Reliability
Load balancing plays a critical role in fault tolerance. It distributes incoming requests across multiple servers to ensure that no single server becomes overloaded.
Benefits include:
- Improved performance
- Better resource utilization
- Increased availability
Modern distributed systems often use intelligent load balancers that monitor server health and route traffic only to operational nodes.
Circuit Breaker Pattern
The circuit breaker pattern prevents cascading failures across services.
In a microservices architecture, services often depend on each other. If one service becomes slow or unavailable, dependent services may also fail.
A circuit breaker detects repeated failures and temporarily blocks requests to the failing service. This allows the system to recover without affecting other components.
Benefits include:
- Preventing system-wide outages
- Reducing unnecessary load
- Improving recovery time
Monitoring and Observability
Fault tolerance depends heavily on effective monitoring.
Engineers must detect failures quickly to ensure systems recover properly.
Key observability tools include:
- Metrics monitoring
- Distributed tracing
- Centralized logging
- Health checks
Monitoring platforms can automatically trigger alerts when anomalies occur, allowing engineers to respond quickly.
Handling Network Partitions
One of the biggest challenges in distributed systems is network partitioning, where nodes lose communication with each other.
The CAP theorem explains that distributed systems can only guarantee two of the following three properties:
- Consistency
- Availability
- Partition tolerance
Since network failures are inevitable, most modern distributed systems prioritize availability and partition tolerance while maintaining eventual consistency.
Chaos Engineering
Leading technology companies intentionally test system resilience using chaos engineering.
This practice involves deliberately introducing failures into production systems to observe how they respond.
Examples include:
- Randomly shutting down servers
- Simulating network latency
- Overloading services
These experiments help engineers identify weaknesses before real failures occur.
Real-World Applications
Fault-tolerant distributed systems power many modern technologies.
Cloud Platforms
Cloud services rely on distributed architectures to ensure high availability across multiple data centers.
Streaming Platforms
Video streaming services must remain operational despite heavy traffic and server failures.
Financial Systems
Online banking and payment systems require extreme reliability to maintain trust and prevent financial loss.
Global Applications
Large-scale platforms serving millions of users worldwide depend on distributed systems for scalability and uptime.
Best Practices for Building Fault-Tolerant Systems
To build reliable distributed systems, engineers should follow several best practices:
- Design for failure from the beginning
- Use redundancy and replication
- Implement automated failover
- Monitor system health continuously
- Use circuit breakers to isolate failures
- Test resilience using chaos engineering
These practices ensure systems remain reliable even under unexpected conditions.
Conclusion
Failures are unavoidable in distributed systems, but well-designed architectures can minimize their impact. By implementing redundancy, replication, load balancing, failover strategies, and strong observability, engineers can build systems that remain operational even when components fail.
Fault-tolerant distributed systems form the backbone of modern digital infrastructure. As applications continue to scale globally, designing resilient systems will remain one of the most important challenges in software engineering.

